A Data Centre Caught Fire in the Netherlands. IBM Cloud Went Dark. Nobody Noticed for Hours.
On the morning of May 7, a fire broke out at a data centre in Almere in the Netherlands. By the time firefighters brought it under control that evening, IBM Cloud’s entire Amsterdam region had gone offline, Utrecht University had closed its campus, GP surgeries and pharmacies had lost access to their systems, and the emergency button system used by bus and tram drivers across an entire Dutch province had stopped working.
The data centre itself handled it well. Every employee got out safely. No servers caught fire. The operator responded quickly and communicated clearly. None of that stopped dozens of organisations from going dark for days, and some are still waiting for power to be restored as of today.
The story is worth paying attention to if your business or website depends on anything hosted online, because the lesson has nothing to do with the fire.
What Happened
NorthC Datacenters runs 25 data centres across the Netherlands, Germany, and Switzerland. Their facility on Rondebeltweg in Almere is part of their core Dutch network: an 11 megawatt building spread across 26,000 square metres, built to Tier 3+ standards with fully redundant power and cooling.
At around 8:45 AM, a fire broke out in the building’s rear technical section, the part of the facility that houses emergency power supplies, cooling systems, and diesel backup generators. Firefighters declared a regional emergency and the response escalated within 30 minutes. A crash tender was called in from Lelystad Airport to cool a diesel tank on site. The blaze was not fully controlled until around 8:50 PM, around 12 hours later.
NorthC shut off power to the data halls on the fire brigade’s instructions. The servers themselves were unaffected. But with no power and no cooling, everything hosted in the building went offline.
The Scale of the Disruption
The list of affected organisations gives you a sense of how far the ripple travelled.
IBM Cloud confirmed that its Amsterdam 03 region went down because of the fire. For at least four hours, customers across Europe couldn’t access resources hosted there. The detail that made headlines beyond the outage itself: IBM’s own status page showed nothing during those four hours. No incidents listed, no degraded services, no acknowledgment that a major European data centre had gone dark. Third-party monitoring tools flagged the outage well before IBM said a word publicly.
Utrecht University told students and staff the fire was having “a big impact” and closed for the day. The Dutch national statistics bureau CBS closed most of its buildings. GP practices and pharmacies across the Netherlands lost access to patient management systems. A local water board reported outages. The Chamber of Commerce went down.
The most striking case involved public transport. Transdev, which runs bus and tram services across Utrecht province, lost contact with its regional control centre because the control centre’s servers were hosted at the Almere facility. The in-vehicle emergency button that allows drivers to call for immediate assistance in a safety incident stopped working. The reason: those servers had never been moved to a backup location.
Recovery has taken longer than expected. NorthC estimated up to 72 hours to restore power, requiring generators, UPS systems, distribution panels, and over a kilometre of cable to be installed. That deadline has already been missed. As of today, power is now expected to be restored on May 13 at noon, after the delivery of a critical component from a European supplier was delayed.
What This Has to Do With Your Website
NorthC did not fail here in any meaningful sense. They build to Tier 3+ standards. Their people got out. Their CEO responded publicly within hours. The fire was in the technical facilities, not the server rooms, and no data was reported lost. A competent operator dealing with a bad situation.
The failure was in the organisations that had everything in one place with no fallback.
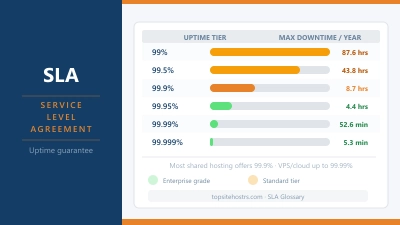
That’s the thing about uptime guarantees. A host can promise you 99.9% uptime and mean it entirely honestly. Their servers can be solid, their network reliable, their team experienced. And then a fire breaks out in the building next to the generators, and the whole facility goes dark for a week regardless. The guarantee doesn’t cover acts of physics.
When you’re choosing a hosting provider, the uptime percentage matters less than the architecture behind it. A few questions worth asking:
How many data centres does your host use? A provider running your site from a single location is a single point of failure. Providers like Hetzner and IONOS operate multiple European data centres. If one location has a problem, traffic routes to another.
What does their backup policy actually cover? Backups protect your data. They don’t keep your site online during an outage unless the host is actually running from those backups at a secondary location. These are different things, and a lot of hosts describe the first while implying the second.
How do they communicate when something goes wrong? The IBM silence during those four hours matters. A host that goes quiet when its infrastructure is on fire is a host that leaves you discovering the problem yourself. Check whether your provider has a public status page, whether they update it proactively, and whether other users’ experiences suggest they actually do.
You can check if your site is responding at any time using the TSH Website Down Checker. But the more useful preparation is making sure your site is on infrastructure that doesn’t rely on a single building staying intact.
The Practical Checklist
Before you move on, it’s worth taking five minutes with your current hosting setup:
- Find out how many data centres your host uses and where they are
- Check whether your plan includes automatic failover or whether redundancy costs extra
- Look up your host’s status page and bookmark it
- Confirm your backup schedule and where those backups are stored
- If you’re on a plan with a 99.9% uptime SLA, read what the compensation policy actually says
The Almere fire is an extreme example. Most hosting outages are far smaller in scale. But the cause is usually the same: too much reliance on one thing working perfectly, and no plan for when it doesn’t.
NorthC will restore power on Wednesday. The organisations that had a proper fallback were back online within hours of May 7. The ones that didn’t are still waiting.